
Are we about to enter a dark age of data journalism?
The internet has made it possible to see the world’s information without moving a muscle, not matter how old that information is. You can absorb the first news page of The Guardian, from May 1821, which had data journalism at its heart, even then.
And the web has revolutionised online journalism so that the way we consume the news changes daily; and the basics of modern data journalism are grounded in that ability to visualise that data in more and more sophisticated ways.
It has also made the archiving of news content easier. In the past, archivists in each organisation would preside over rooms full of old clippings and background information. The web made that process straightforward: everything would be archived online and those collections of the past would even become sources of present-day content, such as the New York Times’ archive, which is regularly sourced and raided by both academics and journalists.
But data journalism is not part of these archives. Much of it has become a victim of code rot – allowed to collapse or degrade so much that as software libraries update or improve, it is left far behind. Now, try and find examples of this work and as likely as not you will end up at a 404 page.

Data journalism itself also has a long history, certainly predating 2009. You can see it in the first fall of Abraham Lincoln or in the work of Philip Meyer in investigating the causes of the Detroit Riots. But the thing is: you can still see that work. Created in Print before the word ‘interactive’ had even been coined, it is kept so you can use it as inspiration. Without Precision Journalism, would Reading the Riots even have existed? The past (by which I mean less than five years ago) has a lot to teach us about the way we work today.
Paul Bradshaw has collated examples of modern data journalism, asking “is there a canon of data journalism?”. And while Minard’s famous chart or Florence Nightingale’s “butterflies” still exist, it is striking how much of it has vanished forever. This is just a sample:
ChicagoCrime.org

The progenitor of interactive news databases in the form you can see them at places like ProPublica, started by the godfather of modern data journalism, Adrian Holovaty (This May was its 10th anniversary). For years it produced just a 404 page. Now it links to a tiny section of EveryBlock.
The US Congress Votes Database
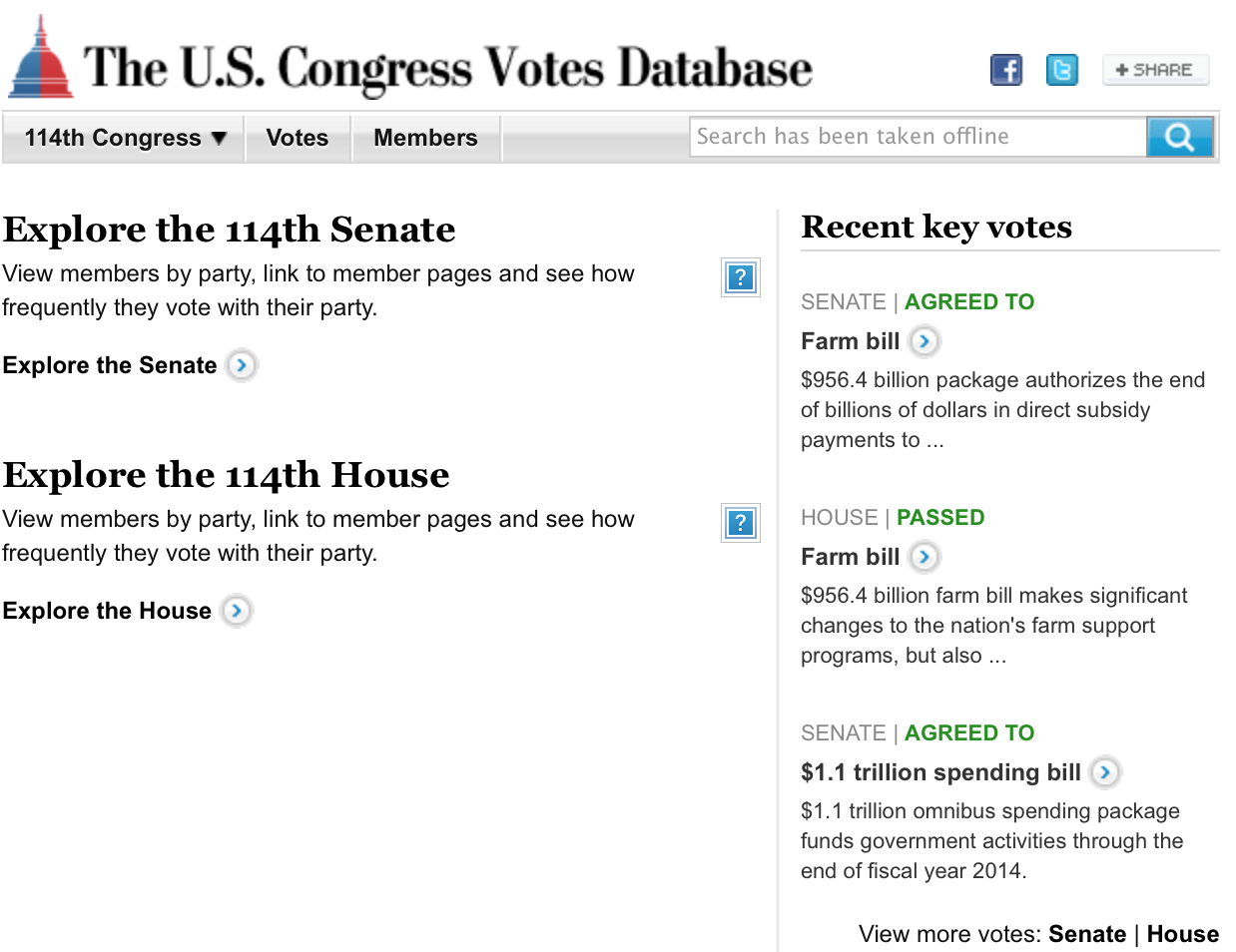
Frozen on a Feb 2014 vote, a tiny ‘this page has been archived’ note at at the top an inadequate replacement for a project that has no equivalent now.
MPs expenses

It would be possible to fill this article with examples of things I worked on that no longer work at The Guardian — the World Data Explorer or the Libya bombing interactive, for instance. But I’ve chosen this because it was the first large-scale news room crowdsourcing exercise, switched off because it couldn’t be maintained. Now no-longer even viewable.
Fixing DC’s Schools
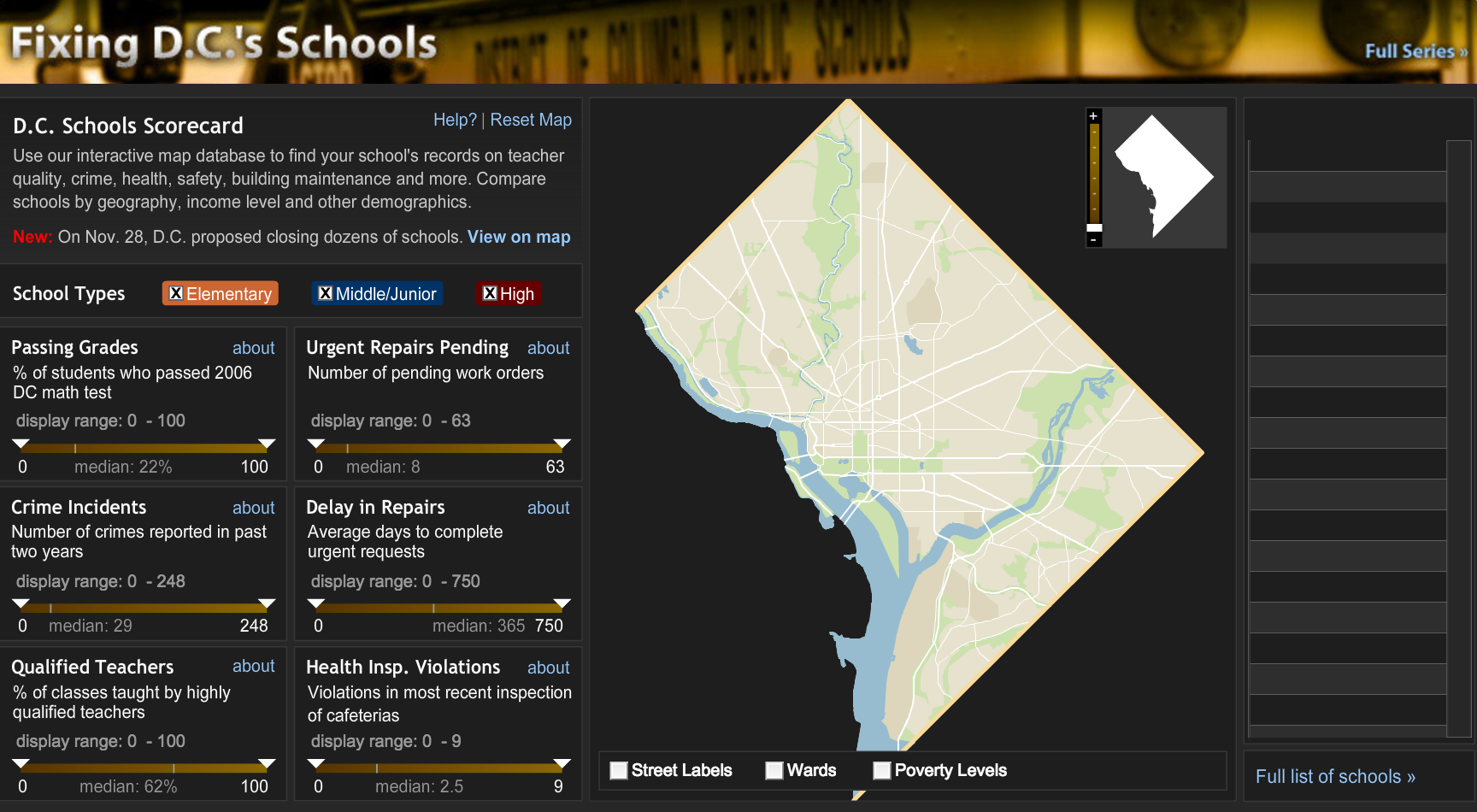
Another pioneering piece of work from Holovaty — a forerunner of apps that are now commonplace among local media sources — the front page leads nowhere and the interactive design doesn’t work anymore.
Represent, from the New York Times
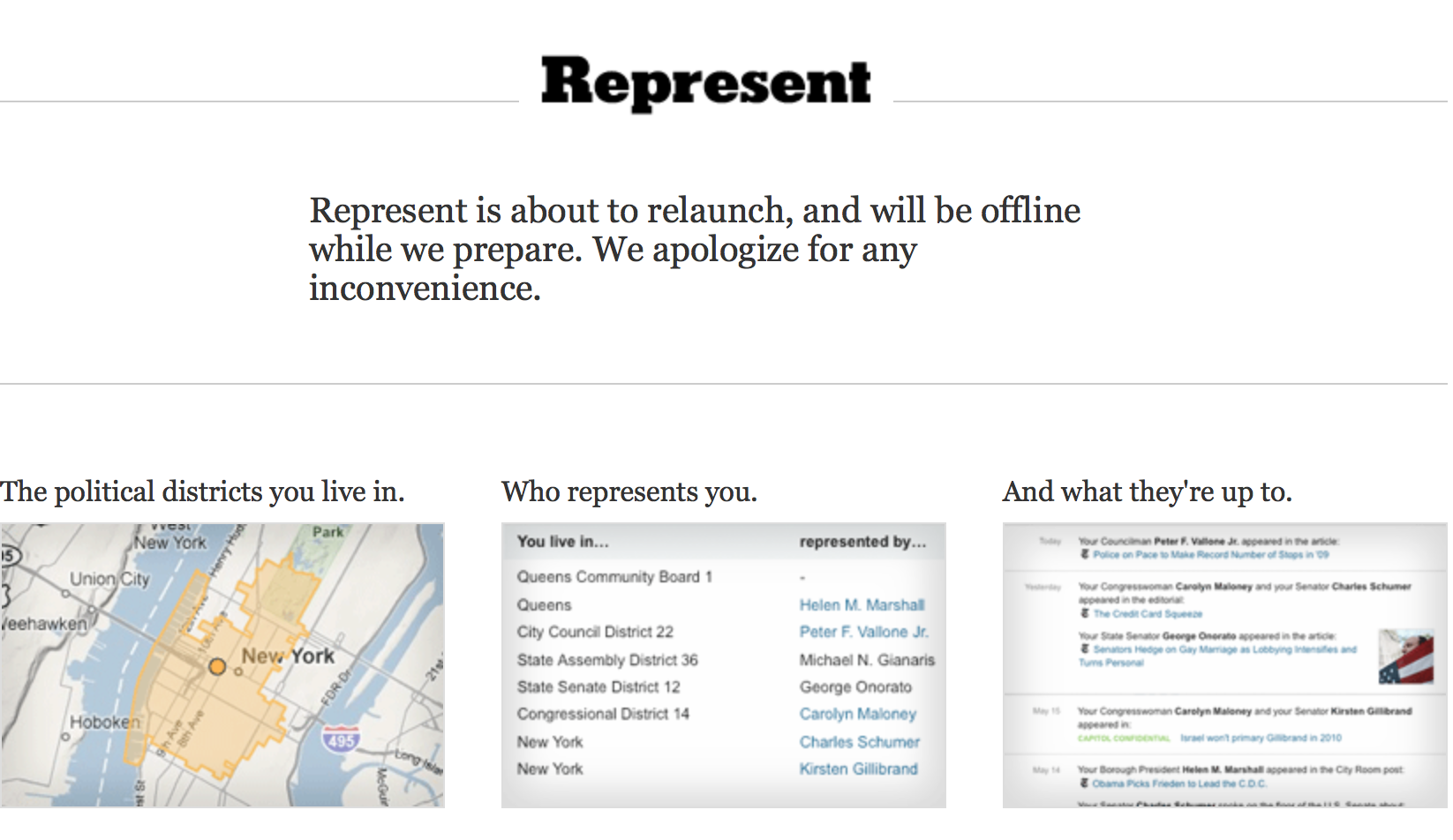
This page has been ‘about to relaunch’ for some time now (some say years). The site originally let people in New York find their congressmen and track all sorts of things about them.
It’s an issue across journalism. In The Atlantic last week Adrianne LeFrance wrote how key pieces of journalism are disappearing from the web
“If you want to save something online, you have to decide to save it. Ephemerality is built into the very architecture of the web, which was intended to be a messaging system, not a library.”
If even Pullitzer prize winning articles are at risk, where does that leave everyday data journalism?
At the same time, for many publishers every word, no matter how facile or pointless is saved as if it were a work of studied genius. This is the fantastic thing about archives: they give you a picture of a world from the past, one that can shape how you produce the future. But it’s only the words that are saved. Meanwhile a map, interactive guide or even just a set of interactive charts will vanish as if they never ever existed.
Data journalism, at its best, bridges the gap between those who have the data and those who want to understand it. It raises data from the prerogative of the few into the consciousness of the many. It can change the world, illuminating that which others would rather keep secret and misunderstood.
But if we’re not careful, this golden age of data journalism will only be remembered in a few animated gifs, texty analysis pieces and CSV downloads. Data will have returned to those who always owned it in the past; the rest of us will have to keep reinventing the wheel.
Nobody says archiving is easy, but what will be left otherwise? This article will. Plainly ironic: an article about the disappearing web left to survive. As will long academic and dry pieces of data analysis. But the apps, charts and visuals that bring them to life? They will vanish as if they never existed.
It’s time for a Data Journalism Archive. Before we forget everything we know.





Leave a comment