First published on Guardian Data
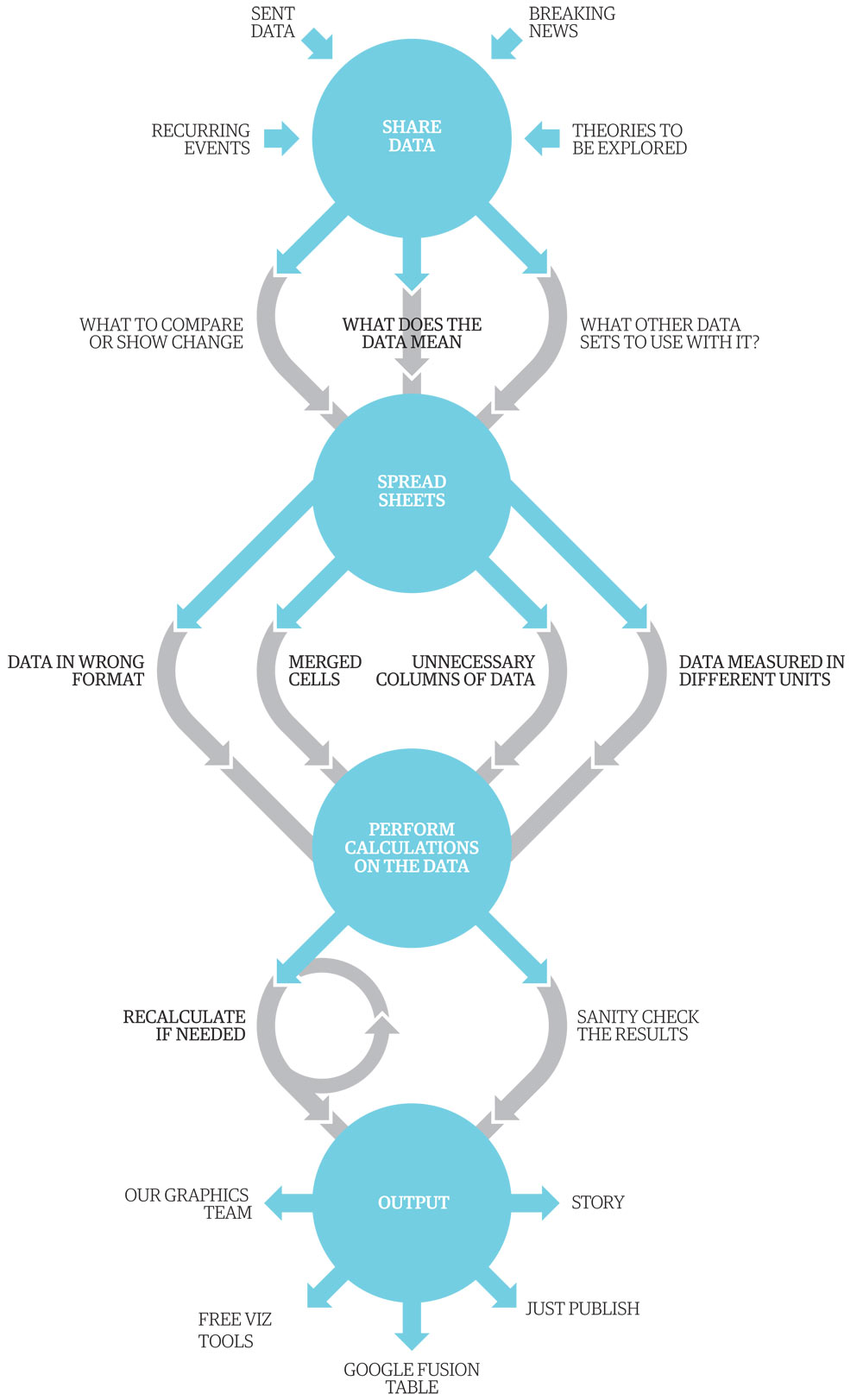
Before a dataset results in a data journalism story, there’s a whole process of sifting and finessing and generally sorting the data out. The split is roughly 70% tidying up the data, 30% doing the fun stuff of visualising and presenting it. So, how do we get through that 70%?
Guardian graphic artist Mark McCormick has helped us visualise that process. So, yes, this is a graphic about how we produce data that often results in, er, graphics. A data visualisation about data visualisations, if you will.
You can get a pdf of this here
Each of these steps could be a piece in itself – and over the next few weeks, we will break them down. But, in short, it goes something like this:
• We locate the data or receive it from a variety of sources, from breaking news stories, government data, journalists’ research and so on
• We then start looking at what we can do with the data – do we need to mash it up with another dataset? How can we show changes over time?
• Those spreadsheets often have to be seriously tidied up – all those extraneous columns and weirdly merged cells really don’t help. And that’s assuming it’s not a PDF, the worst format for data known to humankind
• Now we’re getting there. Next up we can actually start to perform the calculations that will tell us if there’s a story or not – and then sanity check them to see if it just sounds wrong
• At the end of that process is the output – will it be a story or a graphic or a visualisation, and what tools will we use?
You can get a pdf of this here. What have we missed – or how do you do it?





Leave a comment